Dustin Marshall
Research Engineer with a BA from UC Berkeley and an MSc from UChicago. 8+ yrs of exp in SWE/DS/Econ with a focus on building helpful AI applications.
Currently with the Innovation Lab at Consumer Reports, previously with the Data-driven Digital Agriculture team at the World Bank, the Development Innovation Lab (DIL) at UChicago under Nobel laureate Michael Kremer, the Rockefeller Foundation's Data Science Team, and the Center for Effective Global Action (CEGA) at UC Berkeley.
Project Portfolio
Consumer Research RAG Chat App
Currently leading the development of AskCR, Consumer Report’s flagship RAG chat application, from concept, to pilot, to beta, to available to CR’s 6+ million members via standalone mobile and web apps. AskCR uses Consumer Report’s data to answer questions about product ratings, reviews, and more. We use custom query refinement, intent + topic routing, text-2-SQL search over structed data, and hybrid semantic + keyword search over unstructered data. The mobile app is built in React Native, the web app is built in Next.js, and the backend is built in Python. The application is closed-source, but we’ve published blog posts on the early stages of the system architecture.
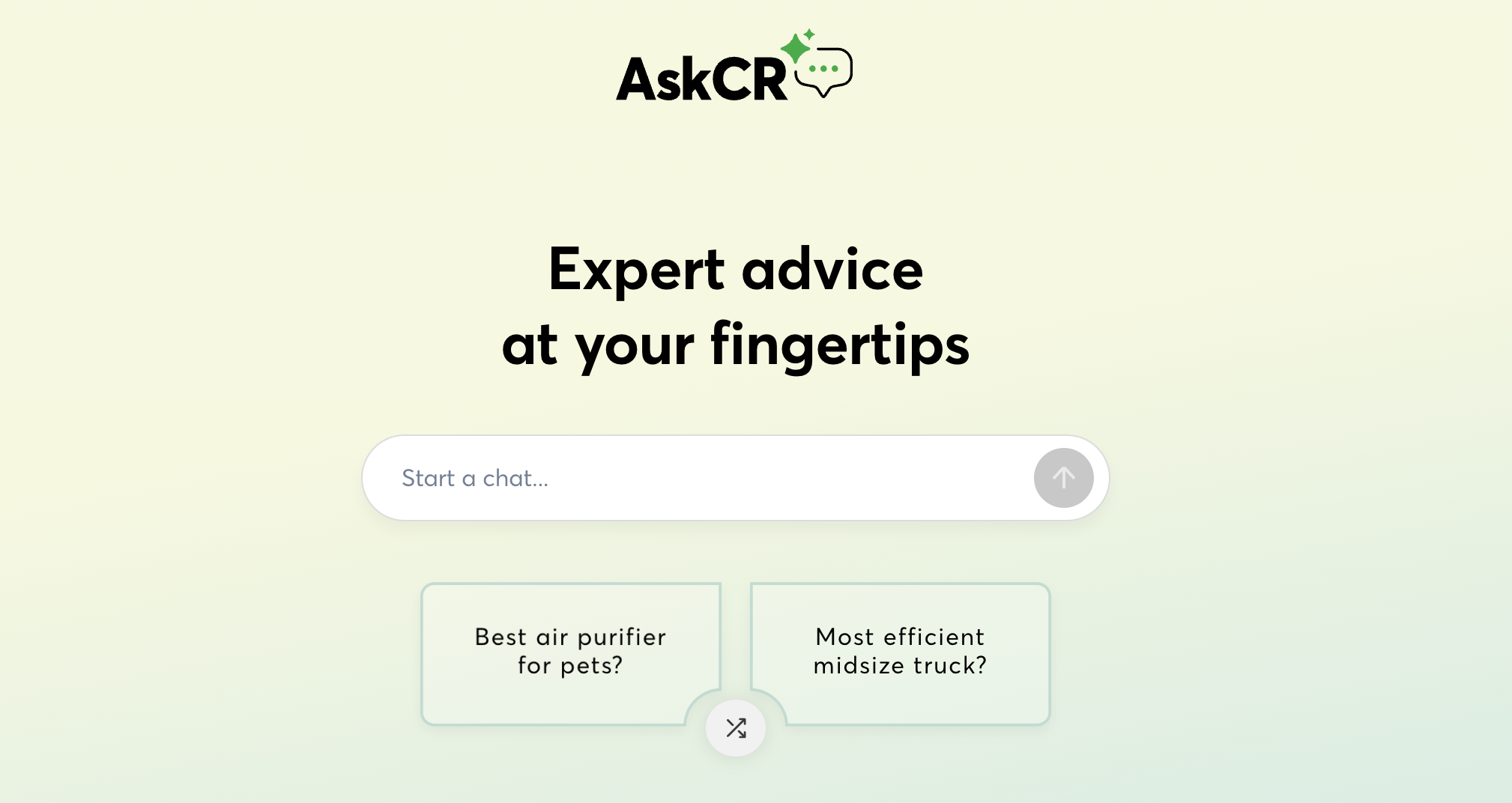
Data Discovery & Analysis Chat App
Created data discovery and analysis RAG chat app prototype with LLM orchestration that includes a first-stage, search step using a hybrid vector + metadata search in Pinecone and OpenAI’s Assistants API with custom functions, then a second-stage, analysis step using RAG retrieval for text data or a code interpreter for tabular data, with the frontend deployed on Streamlit (code). The application is fully open-source on GitHub.
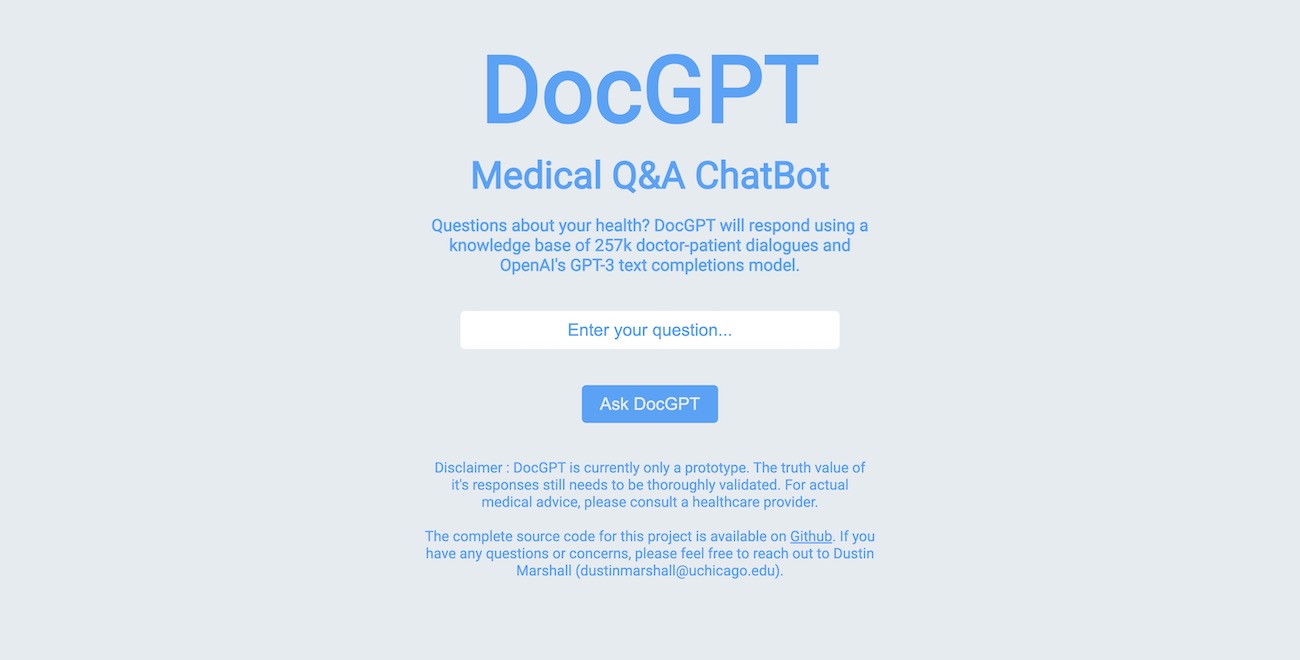
Medical RAG Chat App
During a Big Data and Development course for UChicago’s MSc in Computational Analysis and Public Policy in Winter 2023, I coded and deployed a cloud-based medical AI chatbot using OpenAI’s Completions and Embeddings API endpoints. I used prompt engineering and text embeddings drawn from a knowledge base of 257k doctor-patient dialogues to improve model response. I wrote an accompanying research design for a health intervention using the app. The application is fully open-source on GitHub.
Genomic Annotation Service Application
During a Cloud Computing course in UChicago’s Computer Science Department in Spring 2023, I built a custom cloud application with AWS. I used a custom Flask API, EC2 instances for frontend, backend, and utility services, S3 object storage buckets for inputs and outputs, a DynamoDB database for storing user and job data, Lambda functions for maintaining serverless scalable workflows, and SNS messages + SQS queues for communicating between the distributed systems. The Github repo for this project is private, but I’ve made the exported code available here.
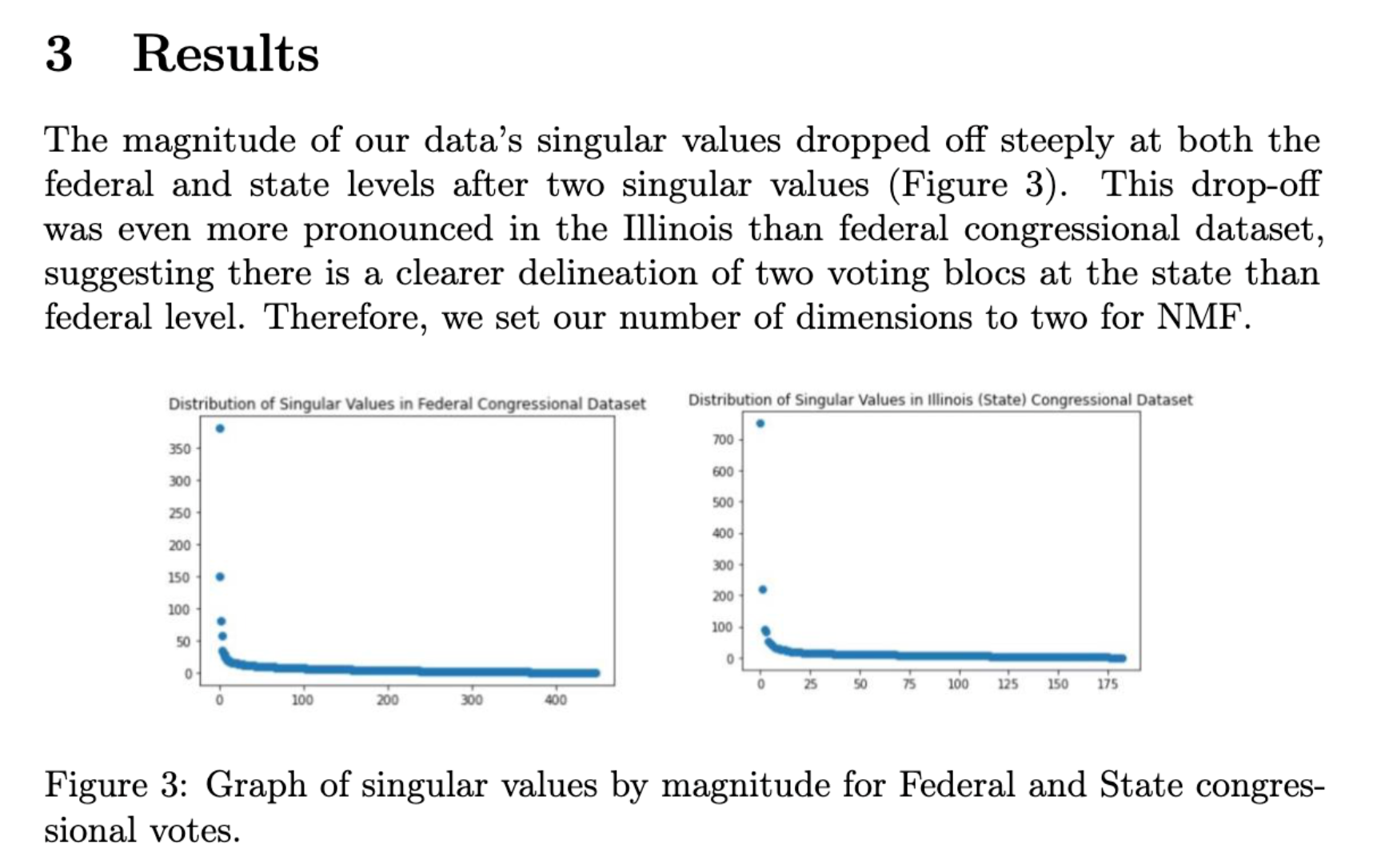
Using Singular Value Decomposition to Detect Partisan Voting
During a Mathematical Foundations of Machine Learning course in UChicago’s Computer Science Department in Fall 2022, I co-authored an ML analysis of federal and state voting records. We used singular value decomposition and non-negative matrix factorization to detect partisanship in voting behavior, finding two clear voting blocs at both the national and state level that align with party affiliation. The code and accompanying academic paper are available on GitHub.
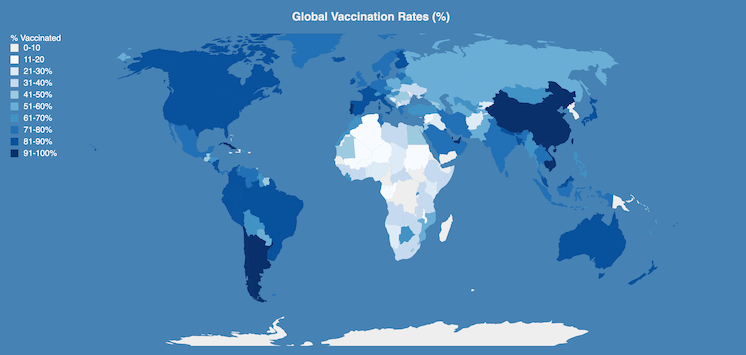
D3 Visualization for Vaccine Hesitency Chatbot Intervention
During a Data Visualization course for UChicago’s MSc in Computational Analysis and Public Policy in Fall 2022, I created a data vizialization in D3.js using the preliminary results of an ongoing chatbot intervention to improve vaccine acceptance in Kenya and Nigeria with Prof. Molly Offer-Westort and DIL Director Leah Rosenzweig. The visualization is coded using the JavaScript library D3.js, which is used to produce dynamic, interactive data visualizations in web browsers. It includes a chloropleth map, grouped bar charts, and heatmaps. The code is available on GitHub.
Text Classification Model to Improve Grantee Discovery
During an internship with the Rockefeller Foundation’s Data Science team in Summer 2022, I worked on a project mapping the non-profit space with natural language processing and machine learning. I built a subject classification model to classify their corpus of grant proposals to aid grantee discovery. The model is open-source on GitHub and a blog post detailing the process was published on a popular machine learning blog on Medium.
Predicting Gentrification using Tract-level Characteristics
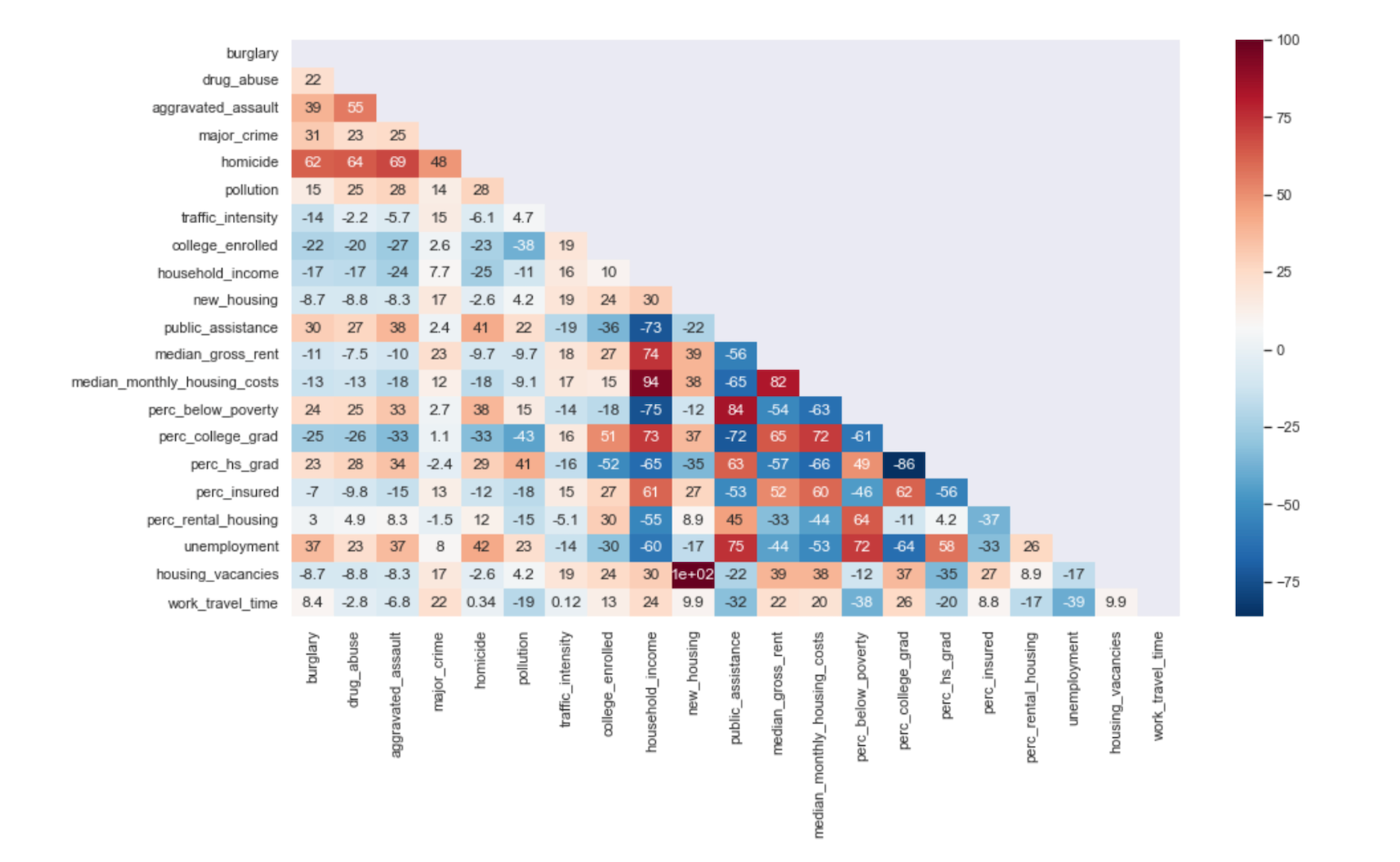
During a Machine Learning course for UChicago’s MSc in Computational Analysis and Public Policy in Spring 2022, my group used 2016 census tract data of neighborhood characteristics to predict a binary classification of a neighborhood’s gentrification status in 2019. The dataset contained 778 census tracts with 22 feature variables measuring socioeconomic status, educational attainment, criminal activity, pollution level, transportation equity and housing equity. The annalysis compared the F1-score performance of logistic regression, decision tree, random forest, and gradient-boosted decision tree models. The code and final report are available on GitHub.
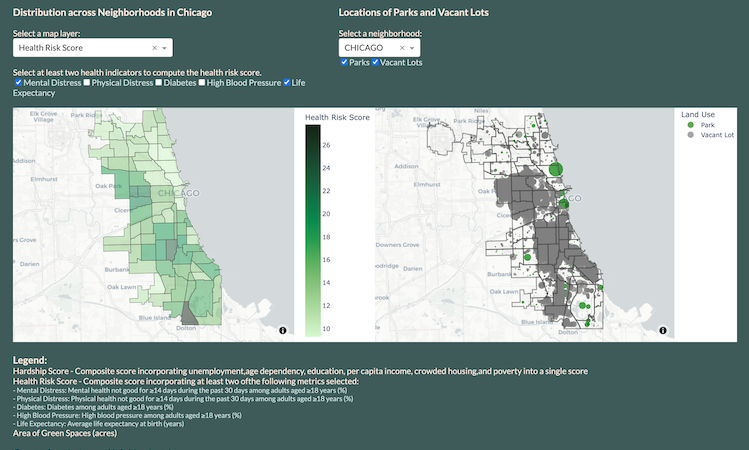
Interactive Dashboard Mapping Parks and Underutilized Public Land
During a Computer Science course for UChicago’s MSc in Computational Analysis and Public Policy in Winter 2022, my group coded a data visualization interface in Dash. The interface serves as a tool for urban planners to identify neighborhoods with disproportionately few green spaces and many vacant lots to be considered for conversion. My contribution focused on collecting, cleaning, and wrangling the data on green spaces and vacant lots using the City of Chicago and Cook County’s APIs. The code and written report are available on GitHub.